A software implementation of this project using the PyTorch framework can be found in our GitHub repository. It is released under the GPLv3 license for academic usage. For any commercial purpose, please contact the authors.


 {#
{# Precision agriculture heavily relies on plant detection and segmentation which is often challenging due to their varied appearance throughout their growth cycle. Additionally, the lack of labeled datasets encompassing different crops hinders the development of fully-supervised plant detection and segmentation approaches. Self-supervised learning (SSL) techniques help combat the outlined label deficiency by pretraining the network on pseudo labels obtained from self-derived pretext tasks before finetuning on the downstream target task. The pretraining step enables the network to learn the underlying semantics of the image which helps it better adapt to a wide range of relevant tasks and datasets.
Existing SSL approaches in the agricultural domain are based on learning techniques tailored for ImageNet classification or rely on the color-suspicable NDVI metric. Our proposed self-supervised INoD approach demonstrates exceptional performance for a range of dense prediction tasks such as object detection, semantic segmentation, and instance segmentation. Find out more about our novel self-supervised framework in the approach section!
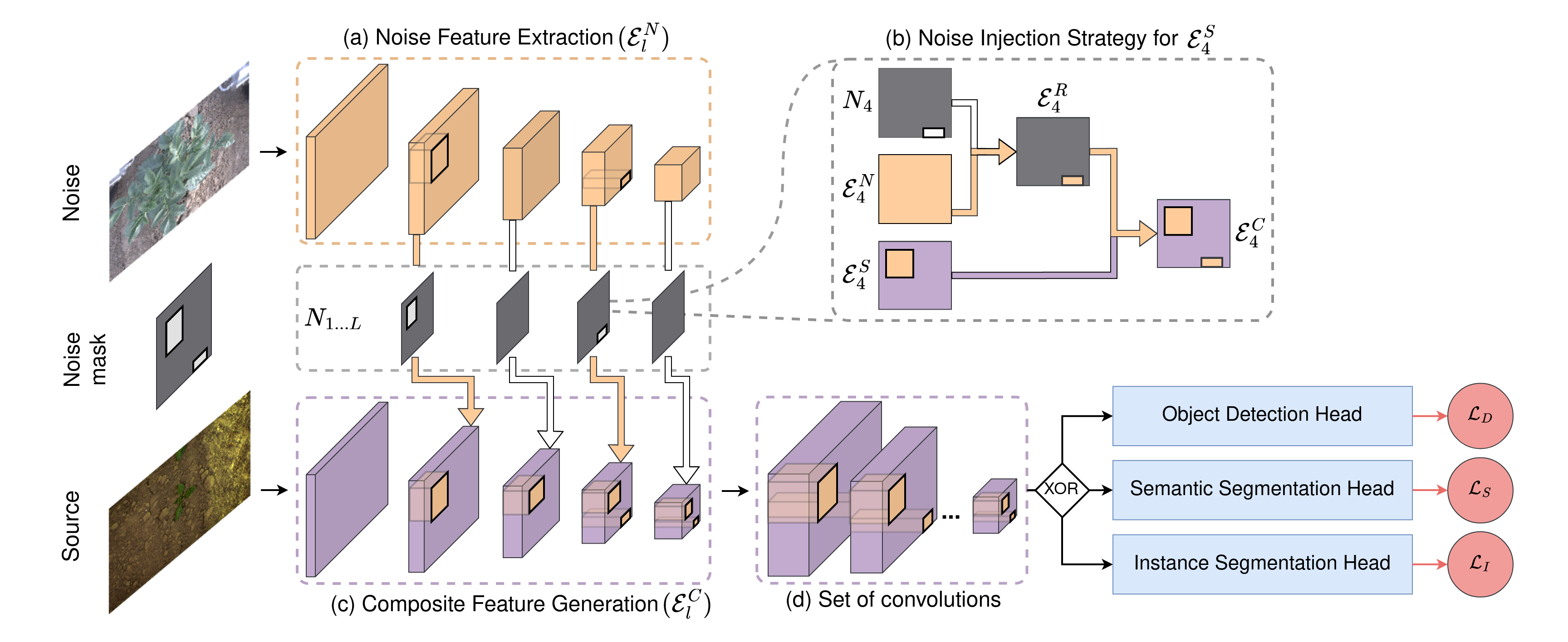
The goal of injected feature discrimination is to make the network learn unequivocal representations of objects from one dataset while observing them alongside objects from a disjoint dataset. Accordingly, the pretraining is based on the premise of injecting features from a disjoint noise dataset into different feature levels of the original source dataset during its convolutional encoding. The network is then trained to determine the dataset affiliation of the resultant feature map which enables learning rich discriminative feature representations for different objects in the image.
We use an off-the-shelf network backbone to compute multi-scale feature maps for the noise image {\(ε^N_1, ε^N_2, ..., ε^N_L\)} (Figure(a)). Second, we generate random layer-specific binary noise masks, \(N_{l}\), for each scale \(l\) to determine the spatial locations at which the noise features are injected into the source features. Third, we extract region-specific noise features, \(ε^R_l\), by multiplying each of the multi-scale noise features, \(ε^N_{l}\), with their corresponding layer-specific noise mask \(N_l\). After, we iteratively inject \(ε^R_l\) at equivalent locations in the source feature map \(ε^S_{l}\) to generate a composite feature map \(ε^C_{l} = f(ε^N_{l}, ε^S_{l}, N_{l})\) (Figure(b)). We then perform the subsequent source network traversal step of the backbone to generate the next level feature map \(ε^S_{l+1}\). Thus, noise injected in early feature maps is carried through higher layers of the network backbone as shown in Figure(c). Finally, we pass the composite feature maps through a set of convolutional layers to further entangle features and generate coherent multi-scale representations (Figure(d)). We then provide these feature maps as input to downstream task heads such as object detection, semantic segmentation, or instance segmentation to infer the dataset affiliation of the composite feature maps.

We supervise the dataset affiliation of the composite feature map by generating task-specific pseudo labels which correspond to the downstream task.



This is a recent dataset by Fraunhofer IPA which was recorded using an agricultural robot at a potato cultivation facility in the outskirts of Stuttgart, Germany. The robot depicted above comprises a Jai Fusion FS 3200D 10G camera mounted at the bottom of the robot chassis at a height of 0.8 m above the ground. The dataset contains 16,891 images obtained from two different stages in the farming cycle of which a subset of 1,433 images have been annotated with bounding box labels following a peer-reviewed process.
Julia Hindel,
Nikhil Gosala,
Kevin Bregler,
Abhinav Valada
"INoD: Injected Noise Discriminator for Self-Supervised Representation Learning in Agricultural Fields"
This work was partly funded by the German Research Foundation (DFG) Emmy Noether Program grant number 468878300.



